
Neural networks power everything from facial recognition on your phone to real-time translation tools. But what actually is a neural network? And how did it go from a basic brain-inspired model in the 1940s to the engine behind cutting-edge AI?
Ever wondered how your phone recognises your face or how Netflix seems to know exactly what you want to watch next? At the heart of these smart features lies a fascinating concept… neural networks!
Whether you're curious about how machines "learn" or you’ve just heard the term flying around, this guide will walk you through the key concepts in plain English. We’ll cover what neural networks do, how they work, and why they’re everywhere.
What is a Neural Network?
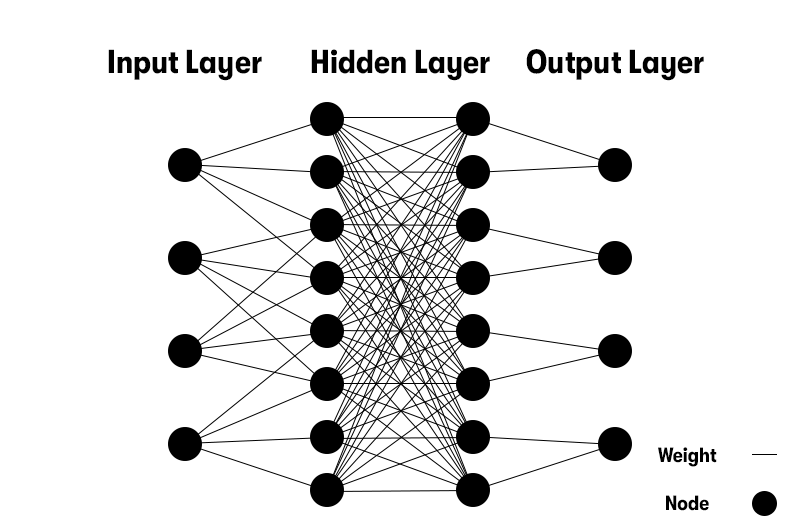
Ever tried to picture how your brain processes information? You’ve got billions of tiny cells, called neurons, all firing off signals to each other at lightning speed. Well, a neural network in computing takes inspiration from that very idea, but swaps out the biological bits for maths and code.
At its simplest, a neural network is a collection of nodes, sometimes called neurons, that are all linked together. Each connection between them has a weight, which is just a fancy way of saying it has a certain level of importance. When information flows through the network, these weights decide how strongly one node influences another.
Think of it like a team of people trying to solve a tricky puzzle. Each person has a piece of the answer, but some have more useful bits than others. By working together and giving a little more attention to the ones with the better clues they can piece the whole thing together. That's exactly what happens in a neural network.
You feed data into the first layer (the input layer), and it gets passed through one or more hidden layers where the real magic happens. These hidden layers transform the input into something the final layer (the output layer) can use to give you a result, like recognising your voice, predicting the weather, or spotting a cat in a photo.
These networks are particularly adept at tasks like image and speech recognition, language translation, and even playing complex games. They've become integral to many applications we use daily.
What makes neural networks particularly clever is their ability to learn from experience. At first, they get things wrong, sometimes hilariously wrong, but they tweak their internal settings each time until they get better and better.
Here's a question: when was the last time you taught yourself a new skill by trial and error? Neural networks learn in pretty much the same way. Only difference? They don't get frustrated or need a cup of tea after a tough session.
The History of Neural Networks
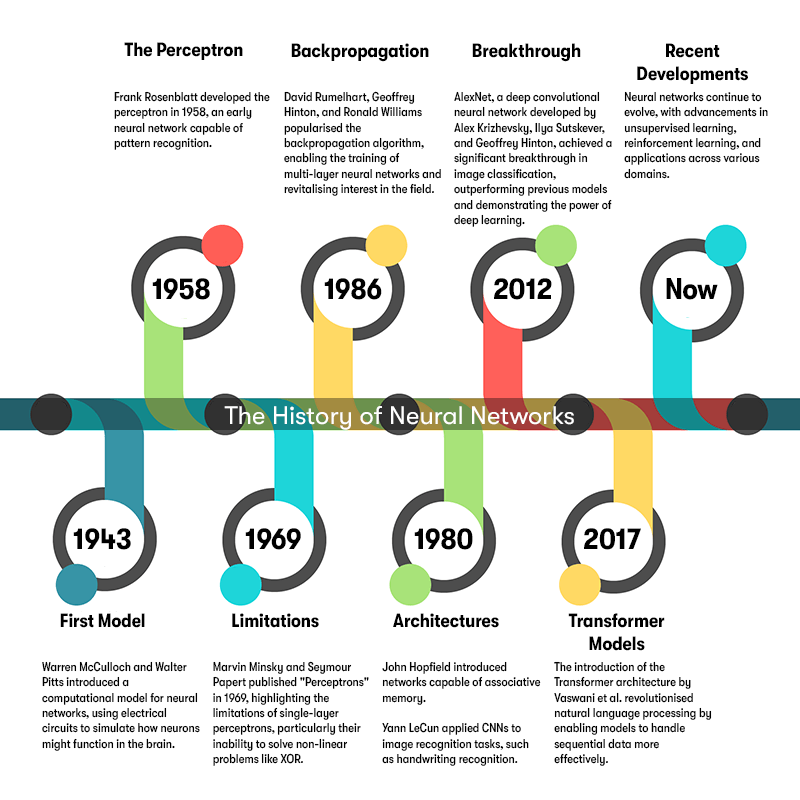
Neural networks have become a cornerstone of modern artificial intelligence, but their journey began long before the recent AI boom. Let's explore the key milestones that have shaped their development.
1943: The First Model
In 1943, Warren McCulloch and Walter Pitts introduced a computational model for neural networks, using electrical circuits to simulate how neurons might function in the brain.
1958: The Perceptron
Frank Rosenblatt developed the perceptron in 1958, an early neural network capable of pattern recognition.
1969: Limitations Revealed
Marvin Minsky and Seymour Papert published "Perceptrons" in 1969, highlighting the limitations of single-layer perceptrons, particularly their inability to solve non-linear problems like XOR.
1986: Backpropagation
In 1986, David Rumelhart, Geoffrey Hinton, and Ronald Williams popularised the backpropagation algorithm, enabling the training of multi-layer neural networks and revitalising interest in the field.
1980s–1990s: Specialised Architectures
During this period, researchers developed specialised neural network architectures:
- Hopfield Networks: John Hopfield introduced networks capable of associative memory.
- Convolutional Neural Networks (CNNs): Yann LeCun applied CNNs to image recognition tasks, such as handwriting recognition.
2012: Deep Learning Breakthrough
In 2012, AlexNet, a deep convolutional neural network developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, achieved a significant breakthrough in image classification, outperforming previous models and demonstrating the power of deep learning.
2017: Transformer Models
The introduction of the Transformer architecture in 2017 by Vaswani et al. revolutionised natural language processing by enabling models to handle sequential data more effectively.
Recent Developments
Neural networks continue to evolve, with advancements in unsupervised learning, reinforcement learning, and applications across various domains, including healthcare, finance, and autonomous systems.
The history of neural networks is a testament to the collaborative efforts of researchers across decades, leading to the sophisticated AI systems we see today.
Types of Neural Networks
Understanding neural network types can help you choose the right architecture for your specific task. Whether it's image recognition, language processing, or data visualisation, there's a neural network suited for the job. Here is a break down some of the most common neural network types:
Feedforward Neural Networks (FNNs)
Think of these as the simplest form of neural networks. Data moves in one direction from input to output without any loops. They're great for tasks where the input and output are straightforward, like image recognition or basic classification problems.
Convolutional Neural Networks (CNNs)
Ever wondered how your phone recognises your face? That's CNNs at work. They're designed to process grid-like data, such as images, by using filters to detect patterns like edges or textures. This makes them ideal for image and video analysis.
Recurrent Neural Networks (RNNs)
When dealing with sequences, like sentences or time-series data, RNNs come into play. They have loops that allow information to persist, making them suitable for tasks like language modelling or speech recognition. However, they can struggle with long sequences due to issues like vanishing gradients.
Long Short-Term Memory Networks (LSTMs)
To address the limitations of RNNs, LSTMs were introduced. They have a more complex architecture that allows them to remember information over longer periods, making them effective for tasks like machine translation or time-series forecasting.
Generative Adversarial Networks (GANs)
GANs are like a game between two neural networks: a generator and a discriminator. The generator creates data, and the discriminator evaluates it. Through this competition, GANs can produce incredibly realistic images, music, and more.
Radial Basis Function Networks (RBFNs)
These networks use radial basis functions as activation functions. They're typically used for function approximation, time-series prediction, and control systems. Their structure allows them to respond to specific regions of the input space.
Modular Neural Networks (MNNs)
MNNs consist of multiple independent networks that work together to solve a problem. Each module handles a specific sub-task, and their outputs are combined to produce the final result. This modularity can lead to more efficient and scalable systems.
Self-Organising Maps (SOMs)
SOMs are used for unsupervised learning tasks. They map high-dimensional data into lower dimensions (usually two) while preserving the topological structure. This makes them useful for data visualisation and clustering.
Deep Belief Networks (DBNs)
DBNs are composed of multiple layers of stochastic, latent variables. They're trained layer by layer and are used for tasks like image recognition and dimensionality reduction.
Transformer Networks
Transformers have revolutionised natural language processing. Unlike RNNs, they process entire sequences simultaneously, allowing for better handling of long-range dependencies. They're the foundation of models like BERT and GPT.
What are Neural Networks Used for?
Neural networks are the unsung heroes behind many of the technologies we use daily. From unlocking your phone with facial recognition to receiving tailored movie recommendations, these systems are working silently in the background. But what exactly are neural networks used for? Let's explore their diverse applications.
Image and Facial Recognition
Neural networks, particularly convolutional neural networks (CNNs), excel at processing visual data. They're the driving force behind facial recognition systems, enabling features like unlocking smartphones or tagging friends in photos. Beyond social media, they're employed in security systems to identify individuals and in medical imaging to detect anomalies.
Natural Language Processing (NLP)
Ever wondered how virtual assistants understand your commands? Neural networks are at the core of NLP tasks, allowing machines to comprehend and generate human language. They're used in applications like language translation, sentiment analysis, and chatbots, making interactions with technology more intuitive.
Autonomous Vehicles
Self-driving cars rely heavily on neural networks to interpret data from sensors and cameras. These systems help vehicles recognise traffic signs, detect pedestrians, and make real-time decisions, ensuring safe navigation through complex environments.
Healthcare Diagnostics
In the medical field, neural networks assist in diagnosing diseases by analysing patient data and medical images. For instance, they can detect early signs of conditions like cancer or diabetic retinopathy, aiding doctors in making accurate diagnoses and treatment plans.
Financial Forecasting
Financial institutions use neural networks to predict market trends and assess risks. By analysing vast amounts of historical data, these systems can forecast stock prices, detect fraudulent transactions, and inform investment strategies.
Personalised Recommendations
Ever noticed how streaming platforms suggest shows you might like? Neural networks analyse your viewing history and preferences to provide tailored recommendations, enhancing user experience across various digital platforms.
Industrial Automation
In manufacturing, neural networks optimise processes by predicting equipment failures and improving quality control. They analyse sensor data to foresee maintenance needs, reducing downtime and increasing efficiency.
Agriculture and Environmental Monitoring
Farmers employ neural networks to monitor crop health and predict yields. By analysing satellite images and sensor data, these systems help in making informed decisions about irrigation, fertilisation, and harvesting.
Gaming and Entertainment
In the gaming industry, neural networks enhance player experiences by creating adaptive AI opponents and generating realistic environments. They also assist in music and art generation, pushing the boundaries of creativity.
Cybersecurity
Protecting digital assets is crucial, and neural networks play a role in identifying and responding to cyber threats. They detect unusual patterns in network traffic, helping to prevent data breaches and unauthorised access.
Neural networks are versatile tools that have found applications across various sectors. As technology advances, their role in shaping our world continues to grow, making our interactions with machines more seamless and intelligent.
Training a Neural Network
In practice a neural network are made up of layers of nodes (sometimes called neurons) that are all linked together. Each connection has a weight, and each node has a threshold. If the output of a node exceeds its threshold, it passes information along to the next layer. Simple enough, right?
But how do you actually get one of these things to learn?
Step One: Gathering your Data
Training a neural network starts long before you feed anything into a computer. You need data. And not just any data. It needs to be clean, relevant, and big enough to teach the network properly.
Ever heard the saying “rubbish in, rubbish out”? If your training data is messy, incomplete, or biased, your model will be too. It’s worth asking yourself: "Is my data telling the story I want the machine to learn?"
You might need thousands, if not millions, of examples depending on what you’re trying to achieve. No small task, but absolutely critical.
Step Two: Setting up the Network
Choosing the right architecture is like picking the right tool for a job. Fancy doing some image recognition? You’ll probably want a convolutional neural network (CNN). Fancy doing something with text or sequences? Then a recurrent neural network (RNN) might be your best bet.
There’s no one-size-fits-all. A bit annoying, maybe, but it keeps things interesting!
At this stage, you’ll define how many layers you want, how many neurons per layer, what activation functions you’re going to use (things like ReLU or sigmoid), and how you’re going to measure performance.
Step Three: Forward Pass
Once you’ve got your data and your architecture, it’s time for the first "forward pass".
This is just a fancy way of saying you feed your inputs into the network, do a load of calculations based on the current weights, and see what comes out the other end.
Spoiler alert, the first results are usually awful. But that's all part of the process.
Step Four: Measuring Error
You now need to figure out how wrong you were.
You’ll compare the output of your network with the real, correct answer, using a loss function. This function will give you a number that tells you how bad the network’s guess was.
Common ones include Mean Squared Error (for regression tasks) or Cross Entropy Loss (for classification). If you’re scratching your head already, don’t worry, it becomes second nature pretty quickly.
How big a mistake would you be comfortable with? Worth having a think.
Step Five: Backpropagation and Optimisation
Here’s where things get a little more interesting.
Based on the error you calculated, you now work backwards through the network, adjusting the weights to try and reduce the error next time around. This process is called backpropagation.
To actually do the weight adjusting, you’ll need an optimiser. The most popular one out there is probably Adam (short for Adaptive Moment Estimation), but you’ll also come across others like SGD (Stochastic Gradient Descent).
Choosing the right optimiser can make a world of difference. Ever tried using a butter knife to cut a steak? Same energy.
Step Six: Rinse and Repeat
You don’t just go through this once. Oh no. You’ll need to run through this process over and over again – across thousands or even millions of iterations (called epochs).
Each time, your network should get a little better at the task you’re setting it.
You’ll also want to split your data into training and validation sets. That way, you can check if your network is genuinely learning, or if it’s just memorising the answers.
How can you tell? If it performs well on training data but badly on validation data, it’s probably overfitting, memorising rather than learning. It's like a student cramming the night before an exam but forgetting everything the next day.
A Few Top Tips:
- Start Small: Don’t try to build the world's biggest network straight off. Train a simple model first and scale up.
- Use Good Data: Seriously. Good data is everything.
- Watch Your Learning Rate: Too high, and you’ll overshoot the answer. Too low, and it’ll take forever to learn.
- Track Your Results: Graphing loss over time can give you brilliant insights into whether your training is actually working.
- Don’t Be Afraid To Fail: Some experiments just won’t work. It’s fine. It’s all part of the game.
Conclusion
So, neural networks aren’t just for boffins in lab coats, they’re shaping the tech you use every day. From recognising your voice to diagnosing illness, they’ve gone from a quirky idea in the 1940s to a key player in how machines learn and adapt. Hopefully, this guide has helped cut through the noise and shown you that while the maths might get heavy under the hood, the core ideas are surprisingly intuitive. Got a new appreciation for how your phone knows you better than your mates? Thought so. If you're curious about machine learning, AI, or fancy trying to train your own model, check out our AI Foundation course.